Hierarchical model fitting with two groups¶
[1]:
%matplotlib inline
import numpy as np
from DMpy import DMModel, Parameter
from DMpy.learning import dual_lr_qlearning
from DMpy.observation import softmax
from DMpy.utils import load_example_outcomes
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
sns.set_style('white')
import os
First we need to load some example outcomes from our experiment. This is a series of ones and zeros representing trials where the subject received a reward or did not receive a reward, and the likelihood of receiving this reward varies over the course of the task.
Load the data¶
[2]:
# Load the data
outcomes = load_example_outcomes()
print outcomes
[ 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1.
1. 0. 0. 1. 1. 1. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.
0. 1. 0. 1. 1. 1. 0. 1. 1. 0. 0. 0. 1. 1. 0. 1. 1. 1.
1. 1. 1. 1. 1. 0. 1. 1. 0. 0. 1. 0. 1. 0. 0. 0. 0. 1.
0. 1. 1. 1. 1. 1. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 1. 1. 1. 1. 0. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 0. 0. 0. 0. 0. 1.
1. 0. 1. 1. 1. 0. 0. 1. 1. 0. 0. 1. 1. 1. 1. 1. 0. 1.
1. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1.
1. 0. 1. 1. 1. 0. 0. 1. 1. 1. 0. 1. 0. 1. 1. 0. 1. 1.
0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 1.]
Define parameters¶
Now we can set up our parameters (currently this needs to be done before simulating data which is a bit backwards).
For this we use the Parameter class in DMpy, which allows us to specify various arguments that determine how the parameter is estimated later on.
We’re going to use a dual-learning rate Rescorla-Wagner model, which assumes that people learn at different rates from better than expected and worse than expected outcomes.
The first parameter is the value parameter, which represents the value of the stimulus as estimated by the model (i.e. this should be highest when the subject sees lots of rewards associated with the stimulus). We’re not attempting to estimate this parameter (although we could), so we specify its distribution as ‘fixed’ rather than giving it an actual distribution. We then specify the “mean” as 0.5, which just provides a starting value, and tell DMpy that it is a dynamic parameter (i.e. its
value should fluctuate over the course of the experiment).
[3]:
value = Parameter('value', 'fixed', mean=0.5, dynamic=True)
Next we’ll define the alpha_p parameter - this is a learning rate parameter for positive outcomes (i.e. outcomes that are better than expected). For the sake of simplicity we’ll also specify this as a fixed parameter, rather than trying to estimate it. Note that here we’ve not used the dynamic argument as this is a constant in the model.
[4]:
alpha_p = Parameter('alpha_p', 'fixed', mean=0.3)
Now we can define the parameter we’re interested in - alpha_n. Because we’re going to estimate this parameter and want to incorporate a prior into this process, we need to provide some information about the distribution we expect this parameter’s values to follow. Here we use a normal distribution with a mean of 0.5 and a variance of 0.1. This parameter should be between zero and one so we use the lower_bound and upper bound arguments to ensure this.
[5]:
alpha_n = Parameter('alpha_n', 'normal', lower_bound=0, upper_bound=1, mean=0.5, variance=0.1)
Finally, the observation model we’ll be using (the softmax model) has one parameter, beta. We’ll leave this fixed at 3 for now.
[6]:
beta = Parameter('beta', 'fixed', mean=3)
Create the model¶
Now we’ve defined out parameters, we can put them into a model along with the functions we imported at the start that define the learning and observation models. For this we use the DMModel class. The arguments here are (learning model function, list of parameters for the learning model, observation model function, list of parameters for the observation model function).
[7]:
model_dual_lr = DMModel(dual_lr_qlearning, [value, alpha_p, alpha_n], softmax, [beta])
Define parameter values for simulation¶
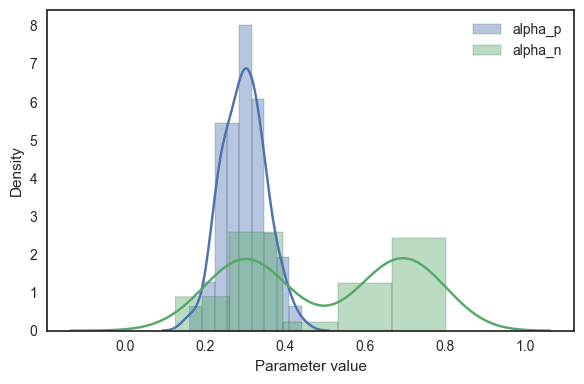
We’re doing to simulate data from a population where alpha_p is unimodally distributed but alpha_n is bimodally distributed - this is similar to what we might hypothesise to be the case in a study of healthy people and people with anxiety, both groups may learn similarly from rewards but anxious people might learn faster from punishments.
To start off, we define a couple of variables specifying how many simulated subjects we want in each group.
[8]:
n_groupA = 50
n_groupB = 50
For the alpha_p parameter, we’ll generate some random values from a normal distribution with a mean of 0.3 and variance of 0.05.
[9]:
alpha_p_values = np.random.normal(0.3, 0.05, n_groupA + n_groupB)
For alpha_n, we’ll generate random values from two separate normal distributions, one with a mean of 0.3 and one with a mean of 0.7, and then join them together using numpy’s concatenate function. This is somewhat like we might expect to see when comparing healthy individuals and patients with something like anxiety - given that we’ve recruited two (theoretically) distinct groups, if a particular parameter has some relevance to the disorder, we would expect its value to have a bimodal distribution.
[10]:
alpha_n_values = np.concatenate([np.random.normal(0.3, 0.05, n_groupA), np.random.normal(0.7, 0.05, n_groupB)])
We can create a histogram of the resulting parameter distributions to see if they appear as they should.
[11]:
sns.distplot(alpha_p_values, label='alpha_p')
sns.distplot(alpha_n_values, label='alpha_n')
plt.legend()
plt.xlabel("Parameter value")
plt.ylabel("Density")
plt.tight_layout()
Now we’ve got the parameter values we want to use, we can plug them into our model and simulate some data. Here we use the simulate method of the model object we defined earlier. We tell it to use the outcomes that we loaded previously, and for the learning model parameters we use the alpha_p and alpha_n values we just defined, along with a list of 100 0.5s for the value parameter (this is the same for every subject). For the observation parameter beta, we give it a list of 100 3s.
Finally, we provide a filename to save the output to.
The simulate method produces two outputs, and we don’t really care about the first one here; this is why I’ve assigned the outputs to the variables _, sim_dual_lr - we use _ in python to indicate a variable we don’t want to use, it’s just somewhere to put an unwanted output from a function. However, we do care about the second output (this is the saved results of the simulation) so we assign that to a proper variable called sim_dual_lr.
[12]:
_, sim_dual_lr = model_dual_lr.simulate(outcomes=outcomes,
learning_parameters={'value': [0.5] * int(n_groupA + n_groupB),
'alpha_p': alpha_p_values,
'alpha_n': alpha_n_values},
observation_parameters={'beta': [3] * int(n_groupA + n_groupB)},
output_file='example_responses.txt')
c:\users\toby\onedrive - university college london\dmpy\DMpy\model.py:815: Warning: Fewer outcome lists than simulated subjects, attempting to use same outcomes for each subject
"subject", Warning)
Finished simulating
Saving simulated responses to example_responses.txt
To illustrate how the simulated behaviour differs between our groups, we can visualise an example of the estimated value from a subject in each group.
[13]:
plt.figure(figsize=(15, 3))
plt.plot(model_dual_lr.simulated['sim_results']['value'][:, 0], label='Low alpha_n')
plt.plot(model_dual_lr.simulated['sim_results']['value'][:, n_groupA], label='High alpha_n')
plt.scatter(range(0, len(outcomes)), outcomes, facecolors='none', linewidths=1, color='black', alpha=0.5)
plt.legend()
plt.xlabel('Trial')
plt.ylabel('Estimated value')
plt.tight_layout()

Fit the model¶
Finally, we need to try fitting our model to the data we’ve simulated - in theory the estimated parameter values should map neatly on to those which which we simulated the data.
To do this, we use the fit method of the model we defined. We provide the location of the simulated data file we just generated, and some other arguments that determine how the model is fit. For the sake of time we’ll use variational inference (http://docs.pymc.io/notebooks/api_quickstart.html#3.3-Variational-inference) with 30000 iterations, maximising the log likelihood (indicated using the logp_method argument). We’ll tell it we want to estimate the model in a hierachical manner, and
ask it to provide parameter recovery plots.
[14]:
model_dual_lr.fit(sim_dual_lr, fit_method='variational', fit_kwargs=dict(n=30000), logp_method='ll', hierarchical=True,
recovery=True)
Loading multi-subject data with 100 subjects, 1 runs per subject
Loaded data, 100 subjects with 200 trials
-------------------Fitting model using ADVI-------------------
Performing hierarchical model fitting for 100 subjects
WARNING (theano.configdefaults): install mkl with `conda install mkl-service`: No module named mkl
WARNING:theano.configdefaults:install mkl with `conda install mkl-service`: No module named mkl
Average Loss = 8,503.8: 100%|███████████████████████████████████████████████████| 30000/30000 [03:28<00:00, 143.72it/s]
Done
PARAMETER ESTIMATES
Subject mean_alpha_n \
0 000_alpha_n.0.239911913062.alpha_p.0.353870957... 0.198758
1 001_alpha_n.0.326650388271.alpha_p.0.260295962... 0.409995
2 002_alpha_n.0.38526084379.alpha_p.0.3175835190... 0.382596
3 003_alpha_n.0.287412537661.alpha_p.0.351517925... 0.276181
4 004_alpha_n.0.127029093794.alpha_p.0.381616585... 0.105853
5 005_alpha_n.0.313926226824.alpha_p.0.341819146... 0.278257
6 006_alpha_n.0.319708806513.alpha_p.0.340604943... 0.308090
7 007_alpha_n.0.214326844532.alpha_p.0.236180639... 0.247346
8 008_alpha_n.0.342896894987.alpha_p.0.294417384... 0.259905
9 009_alpha_n.0.302822004257.alpha_p.0.334889486... 0.321185
10 010_alpha_n.0.296088096179.alpha_p.0.313576648... 0.314779
11 011_alpha_n.0.22867193886.alpha_p.0.3642096706... 0.196515
12 012_alpha_n.0.238568376609.alpha_p.0.289548070... 0.270886
13 013_alpha_n.0.333964691333.alpha_p.0.234918446... 0.354862
14 014_alpha_n.0.313472949321.alpha_p.0.366273420... 0.368069
15 015_alpha_n.0.295060339023.alpha_p.0.262165398... 0.324372
16 016_alpha_n.0.351394542372.alpha_p.0.302112410... 0.356938
17 017_alpha_n.0.412968164679.alpha_p.0.282045739... 0.454299
18 018_alpha_n.0.347359105203.alpha_p.0.309025651... 0.384550
19 019_alpha_n.0.307882861124.alpha_p.0.295786632... 0.394497
20 020_alpha_n.0.418350716018.alpha_p.0.236280025... 0.590481
21 021_alpha_n.0.395825497911.alpha_p.0.269996570... 0.445762
22 022_alpha_n.0.358397872131.alpha_p.0.259608171... 0.437787
23 023_alpha_n.0.351229653278.alpha_p.0.204870263... 0.490488
24 024_alpha_n.0.272532989465.alpha_p.0.346461535... 0.248047
25 025_alpha_n.0.263466390585.alpha_p.0.273563799... 0.238779
26 026_alpha_n.0.292024870096.alpha_p.0.279225737... 0.322490
27 027_alpha_n.0.326721001875.alpha_p.0.302804139... 0.264122
28 028_alpha_n.0.216852274472.alpha_p.0.246366471... 0.276166
29 029_alpha_n.0.374242314125.alpha_p.0.381780714... 0.355090
.. ... ...
70 070_alpha_n.0.735139785761.alpha_p.0.242296922... 0.794309
71 071_alpha_n.0.787999741303.alpha_p.0.293591067... 0.757629
72 072_alpha_n.0.652302002567.alpha_p.0.241690233... 0.736306
73 073_alpha_n.0.596664966336.alpha_p.0.279521996... 0.694942
74 074_alpha_n.0.756506347707.alpha_p.0.305348255... 0.702487
75 075_alpha_n.0.656914459199.alpha_p.0.338551985... 0.547690
76 076_alpha_n.0.736832364979.alpha_p.0.284574453... 0.726080
77 077_alpha_n.0.646009339883.alpha_p.0.339762118... 0.580754
78 078_alpha_n.0.690411868894.alpha_p.0.255010083... 0.704997
79 079_alpha_n.0.737005523294.alpha_p.0.321148537... 0.755732
80 080_alpha_n.0.729536173597.alpha_p.0.262491528... 0.721654
81 081_alpha_n.0.627889937724.alpha_p.0.296678894... 0.635128
82 082_alpha_n.0.606412348772.alpha_p.0.232710801... 0.601708
83 083_alpha_n.0.801927641651.alpha_p.0.295205394... 0.706945
84 084_alpha_n.0.746938799892.alpha_p.0.317898529... 0.657569
85 085_alpha_n.0.774834250401.alpha_p.0.247272148... 0.860098
86 086_alpha_n.0.728600717621.alpha_p.0.286112226... 0.668086
87 087_alpha_n.0.644419502002.alpha_p.0.297611508... 0.536921
88 088_alpha_n.0.641373737281.alpha_p.0.277829957... 0.677182
89 089_alpha_n.0.699335057002.alpha_p.0.333284137... 0.642639
90 090_alpha_n.0.781596062231.alpha_p.0.296919012... 0.642671
91 091_alpha_n.0.771739118279.alpha_p.0.270078145... 0.747638
92 092_alpha_n.0.720652247342.alpha_p.0.307991027... 0.690663
93 093_alpha_n.0.696677046314.alpha_p.0.292139250... 0.728385
94 094_alpha_n.0.659290210509.alpha_p.0.332482401... 0.677133
95 095_alpha_n.0.625585053791.alpha_p.0.229457532... 0.690555
96 096_alpha_n.0.588302185585.alpha_p.0.443040085... 0.491678
97 097_alpha_n.0.736517867318.alpha_p.0.312245819... 0.692688
98 098_alpha_n.0.723096369396.alpha_p.0.230561841... 0.820700
99 099_alpha_n.0.623707975616.alpha_p.0.243020738... 0.735039
sd_alpha_n
0 0.026657
1 0.061491
2 0.046671
3 0.033565
4 0.014569
5 0.042533
6 0.040343
7 0.029951
8 0.031145
9 0.041420
10 0.043617
11 0.025628
12 0.036414
13 0.041051
14 0.043709
15 0.040510
16 0.044247
17 0.052085
18 0.043785
19 0.048921
20 0.079400
21 0.055564
22 0.056049
23 0.052322
24 0.033254
25 0.031677
26 0.044139
27 0.031058
28 0.030785
29 0.047329
.. ...
70 0.113625
71 0.099747
72 0.096569
73 0.081597
74 0.075245
75 0.053918
76 0.083445
77 0.066000
78 0.083837
79 0.087792
80 0.088429
81 0.076321
82 0.075818
83 0.085401
84 0.087157
85 0.092553
86 0.076128
87 0.054600
88 0.075375
89 0.081869
90 0.069996
91 0.092354
92 0.090055
93 0.089417
94 0.074294
95 0.081479
96 0.061801
97 0.078880
98 0.088899
99 0.089021
[100 rows x 3 columns]
Performing parameter recovery tests...
Finished model fitting in 221.128957833 seconds
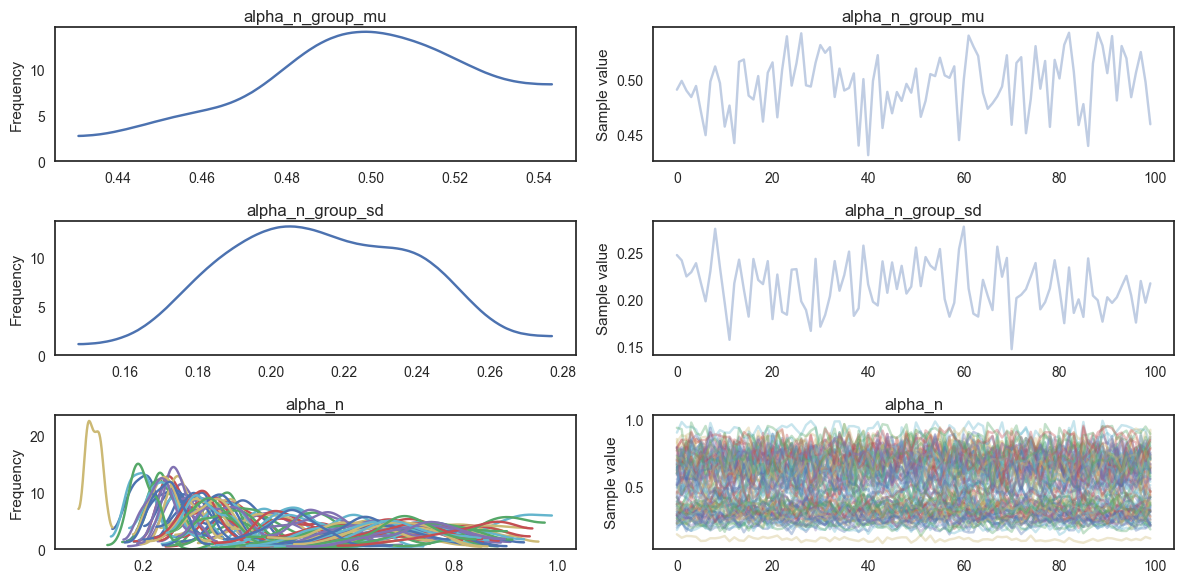
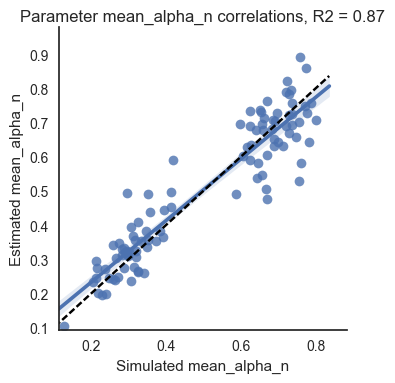
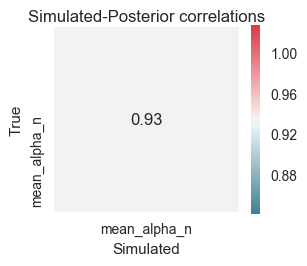
On the whole, this has worked pretty well - the correlation between the simulated and recovered parameters is .94 and the R2 value is .87. However there are a couple of problems - firstly, the group level SD is large (0.2) which means we’re losing some of the benefit of hierarchical estimation methods (this method uses the group-level distribution to constrain the individual subject estimates; a wide group-level distribution isn’t going to constrain these estimates much). Secondly, our individual subject estimates have been drawn slightly towards the group mean. This can be seen in the correlation plot - the black dotted line is the line of equality (simulated value = recovered value) and the fitted line in blue is slightly flatter than this, indicating that higher values have been underestimated while lower values have been overestimated.